![]()
![]()
![]()
|
|
|
|
D espite the forbidding mystique around the act (and word) of "writing", it is not a skill one is born with . People learn how to write, just as they learn how to read, to type, and to operate computers. Ones get better at it the more one writes. We too has obtained the same path and this was our first step towards practical learning.This Assignment was the first experience of ours in the way of learning Mathematical ideas and techniques. We are thankful and grateful to Almighty Allah the omnipotent and omnipresent who has endowed us with knowledge in the patience and encourage in the accomplishment of our task. We are also thankful to our course supervisor Sir Syed Asif Ali for his endless co-operation. INTRODUCTION TO HASHING A function that transforms a key into a table index is called a hash function. If h is hash function and key is key, h(key) is called the hash of key and is the index at which a record with the key should be placed. If r is a record whose key hashes into hr, hr is called the hash key of r. The example of a hash function might be h(k)=key % 1000. The value that h produces should cover the entire set of indices in the table. For example, the function, x%1000 can produce any integer between 0 and 999, depending on the value of x. Two records cannot occupy the same position. Such a situation is called a hash collision or a hash clash. There are two basic methods of dealing with a hash clash. The first technique called rehashing, involves using a secondary hash function on the hash key of the item. The rehash function is applied successively until an empty position is found where the item can be inserted. The second technique, called chaining, builds a linked list of all items whose keys hash to the same values. A good hash function is one that minimizes collisions and spreads the records uniformly throughout the table. That is why it is desirable to have the array size larger than the number of actual records. The larger the range of the hash function, the less likely it is that the two keys yield the same hash value. Of-Course this involves a space/time trade-off. Leaving empty spaces in the array is inefficient in terms of space, but it reduce the necessity of resolving hash clashes and is therefore more efficient in terms of time. DIFFERENT TYPES OF HASH FUNCTIONS One of the first hashing functions and perhaps the most widely accepted are the Division method, which is defined as H(k)= key mod m +1 For some integer divisor m. The operator mod denotes the modulo arithmetic system. In this system the term key mod m has a value which is equal to the remainder of dividing key by m. For example, if key = 35 and m = 11 then H(35)=mod 11+1= 2+1=3 The division method yields a hash value which belongs to the set {1,2…m}. Another hashing function which has been widely used in many applications is the Mid Square method. In this method a key is multiplied by itself and the address is obtained by selecting an appropriate number of bits or digits from the middle of the square. Usually the number of bits or digits chosen depends on the table size and consequently can fit into one computer word of memory. The same position in the square must be used for all the products. Consider a six-digit key 123456. Squaring this key results in the value 15241383936. The Mid Square method has been criticized by some but it has given a good result when applied to certain key sets. In the Folding method a key is partitioned into a number of parts each of which has the same length as the required with the possible exception of the last part. The parts are then added together ignoring the final carry to form an address. If the keys are m binary form the "exclusive -or" operation may be substituted for addition. Folding is a hashing function, which is also useful in converting multiword keys into a single word so that the other hashing functions can be used. A hashing function is referred to as Digit Analysis if it forms addresses by selecting and shifting digits or bits of the original keys. An analysis on a sample of the key set is performed to determine which key positions should be used in forming an address. This hashing transformation techniques has been used in the conjunction with static key set is i.e. key sets that do not change over time. Another hashing technique which has been commonly used in table-handling applications is called the Length Dependent Method .The length of the key is used along with some portion of the key to produce either a table address directly or more commonly a intermediate key which is used. Knott 1975 and Knuth claim that another method the multiplicative hashing function is quite useful. For a non-negative integral key k and constant c such that 0<c<1 the function is h(key)=[m(c*key mod 1) } + 1 Here c*k mod 1 is the fractional part of c k and [ ] denote the greatest integer less than or equal to its contents. The multiplicative hashing function should give good results if the constant c is properly chosen a choice, which is difficult to make. Although some of these methods often give a uniform distribution of keys over addresses yet they play a vital role in the implementation of hashing search mechanism. Good Hash Functions A hash function should be easy and fast to compute. If a hashing scheme is to perform table operations almost instantaneously and in constant time, you certainly must be able to calculate the hash function rapidly. Most of the common hash functions require only a single division (like the modulo function), a single multiplication, or some kind of "bit-level" operation on the internal representation of the search key. In all these cases, the requirement that the hash function to easy and fast to compute is satisfied. A hash function should scatter the data evenly through out the hash table. Unless you use a perfect hash function-which is usually impractical to construct-your hash function typically cannot avoid collisions entirely. For example, to achieve the best performance from a separate-chaining scheme, each entry T[I] should contain approximately the same number of items in its chain; that is, each chain should contain approximately N/TableSize items (and thus no chain should contain significantly more than N/TableSize items). To accomplish this goal, your hash function should scatter the search keys evenly throughout the hash table. PERFORMANCE MEASURE OF HASHING FUNCTIONS A performance measure is needed to compare different hashing function and the measure most widely adopted is the Average Length of Search (ALOS). A hashing function is a many-to-one mapping that is many keys can be transformed into the same address. COLLISION RESOLUTION TECHNIQUES A hashing function can in general map several keys into the same address. When this situation arises the colliding records must be sorted and accessed as determined by Collision Resolution Techniques. There are two broad classes of such techniques open addressing and chaining. The general objective of collision resolution techniques is to attempt to place colliding records elsewhere in the table. This requires the investigation of a series of table position until an empty one is found to accommodate a colliding record. With open addressing if a record with key "k" is mapped to an address location "d" and this location is already occupied then other locations in the table are examined until a free location is found for the new record. If the record with key "k" is deleted then k is set to a special value called Delete, which is not equal to the value of any key. There are several methods for dealing with hash clashes of which some are given below. 1)OPEN HASHING(SEPARATE CHAINING) Another effective method of solving hash clashes is called separate chaining. It involves keeping a distinct linked list for all records whose keys hash into a particular value. For convenience this list contains headers. The usage of an bucket of header nodes of size tabelsize takes place. This array is called hash table, to perform a search operation we use the hash function to determine which list to traverse , afterwards the list is traversed in a normal manner returning the index(position) of the item found. To insert an item in the list we traverse the list to make sure that the item is not already present in the list. In case of a new element , the item is either inserted in the front of the list or at its end. The search and insertion algorithm for separate chaining uses a hash function h, an array bucket , and nodes that contain three fields: k for the key, r for the record, and next as a pointer to the next node in the list. getnode is used to allocate new list node.
}//End Search 2)CLOSED HASHING(OPEN ADDRESSING) Another alternative to resolving collisions with linked list is named as closed hashing. In a closed hashing system, if collisions occurs, alternate cells are tried until an empty cell is found. More formally, in closed hashing we look at three common collision resolution strategies. Let us consider an example of a company with an inventory file in which each record is keyed by a seven digit part number. If there exists a single record for each part an array of 1000 elements can be maintained assuming that the company has not more than 1000 employees. The array is indexed by an integer between 0 and 999 exclusive. The last three digits of the part number are used as the index for the part’s record in the array. It means only the last three digits of the key are used in determining the position of a record. LINEAR PROBING If we consider what happen if it were desired to enter a new part number 0596397 into the table. Using the hash function function key % 1000. H(0596397)=397; therefore the record for that part belongs in position 397 of the array. However the position 397 is already occupied by the record with key4957397. Therefore the record with key 0596397 is placed in the location 398, which is still open. Once that record has been inserted, another record that hashes to either 397 (such as 8764397) or 398 (such as 2194398) is inserted at the next available position, which is 400. This technique is called linear probing and is an example of a general method for resolving hash clashes called rehashing or open addressing. In general, a rehash function, rh, accepts one array index and produces another. If array location h(key) is already occupied by a record with a different key, rh is applied to the value of h(key) to find another location where the record may be placed. If position rh(h(key)) is also occupied, it too is rehashed to see if rh(rh(h(key))) is available. This process continues until an empty location is found. Thus we may write a search and insertion function using hashing as follows.
The number of iteration determines the efficiency of the search. The loop can be excited in one or two ways: either i is set to a value such that table[i]. K equals key (in which case the record is found), or i is set to a value such that the table[i].k equal null-key( in which case an empty position is found and the record may be inserted). It may happen, however that the loop executes forever. There are two possible reasons for this. First the table may be full, so that it is impossible to insert any new records. This situation can be detected by keeping a count of the number of records in the table. When the count equals the table size, no additional insertions are attempted. This phenomenon, where two keys that hash into different values compete with each other in successive rehashes, is called primary clustering. Any rehash function that depends solely on the index to be rehashed causes primary clustering. One way of eliminating primary clustering is to allow the rehash function to depend on the number of times that the function is applied to a particular hash value. QUADRATIC PROBING(QUADRATIC REHASH) Quadratic probing is a collision resolution method that eliminates the primary clustering problem of linear probing. In quadratic probing the collision function is quadratic. You can virtually eliminate primary cluster simply by adjusting the linear probing scheme. Instead of probing consecutive locations from the original hash location table[h(key)],you check locations table[h(key) +l*1], table[h(key)+ 2*2], table[h(key)+32], and so on until you find an available location. Unfortunately, when two items hash into the same location, quadratic probing uses the same probe sequence for each item. This phenomenon-called secondary clustering-delays the resolution of the collision. Another approach is of random permutation of the numbers between f and t, where t equal tablesize-1, the largest index of the table, p1,p2,p3,……,pt and to let the jth rehash of h(key) be (h(key)+ pj) % tablesize. Still a third approach is to let the jth rehash of h(key) be (h(key) + sqr(j) % tablesize. This is called the Quardatic Rehash. Secondary Clustering, in which different keys that hash to the same value follows the same rehash path. One way to eliminate all clustering is double hashing, which involves the use of two hash functions, h1(key) and h2(key). H1 is called a primary hash function, is first used to determine the position at the which the record should be placed. Double hashing, which is yet another open-addressing scheme, drastically reduces clustering. The probe sequences that both linear probing and quadratic probing use are key independent. For example, linear probing inspects the table locations sequentially no matter what the hash key is. In contrast, double hashing defines key-dependent probe sequences. In this scheme, In this scheme the probe sequence still searches the table in a linear order, starting at the location h1(key), But a second hash function h2 determines the size of the steps taken. DELETING ITEMS FROM A HASH TABLE It is difficult to delete items from a hash table uses rehashing for search and insertion. Suppose that record r1 is at position p. To add a record r2 whose key k2 hashes into p, it must be inserted into the first free position from among rh(p), rh(rh(p)),…. Suppose that r1 is then deleted, so that position p becomes empty. A subsequent search for record r2 begins at position h(k2), which is p. But since that position is now empty, the search process may erroneously conclude that record r2 is absent from the table. One possible solution to this problem is to mark a deleted record as "deleted" rather than "empty" and to continue searching whenever a deleted position is encountered in the course of a search. But it is only possible only if the there are a small number of deletions; otherwise an unsuccessful search is required through the entire table because most of the position will be marked deleted rather than empty. When a hash table is nearly full, many items are not in the table on the locations given by their hash keys. Many key comparisions must be made before finding the item. If an item is not in the table ,the entire list of rehash positions must be examined before the fact is determined. There are several techniques for the remedy in this situation. In this technique determined by Amble and Knuth, the set of items that hash into the same locations( i.e their hash keys are same) are maintained in descending order of their keys. b)INSERING AN ITEM: When inserting a key key , if a rehash accesses a key smaller than Key, key and its associated record replace the smaller key in the table and the insertion Process continues with the displaced key. The following steps are involved in searching and inserting through this method. PSEUDOCODIC VERSION OF THE FIRST METHOD
This ordered hash table method can be used with any rehashing technique in which a rehash depends only on the index and the key; it cannot be used with a rehash function that depends on the number of times the item is rehashed. BRENT’S METHOD This method is used to improve the average search time for successful retrievals when double hashing is used. The technique involves rehashing the search argument until an empty slot is found. Then each of the keys in the rehash path is itself rehashed to determine if placing one of those keys in an empty slot would require fewer hashes. If this is the case, the search argument replaces the existing key in the table and the existing key is inserted in its empty rehash slot. The following pseudocode is a search and insertion algorithm. It uses auxiliary routines setempty , which initializes a queue of table indexes to empty :insert , which inserts an index onto a queue : remove , which returns an index removed from a queue: and freequeue, which frees all the nodes of a queue. PSEUDOCODIC VERSION OF THE BRENT’S METHOD
Another method of improving Brent’s algorithm is attributable to Gonnet and Munro and is called binary tree hashing. Every time a key is to be inserted into the table, an almost complete binary tree is constructed. Each node of the tree contains an index into the hash table , it Means the hash table index contained in node(i) will be referred to as index(i) and the key at that position(table[index(i).k) as k(i).key is to as k(-1). The construction of the tree is explained in such a way that the youngest right ancestor of node[i], or yra(i) , as the node number of the father of the youngest ancestor of node(i) The Binary Tree is a constructed in node number order index(0) is set to rh(index((I-1)(2), k(yra(I))). The process continues until k(I) (i.e. table[index(I)].k) equals Nullkey and an empty position is found in table. A series of left pointers through the tree consists of successive rehashes of a particular key and that a right pointer indicates that a new key is being rehashed. Once the tree was been constructed, the keys along the path from the root to the last node are recorded in the high table. If the hash table is static (i.e. if elements are initially inserted and the table remains unchanged for a long series of searches), another recording strategy is to perform all the insertions initially and then to rearrange the elements of the table to absolutely minimize the expected retrieval cost. Hashing may seem to be a voodoo table implementation, but in fact a proper analysis of its average-case efficiency is possible. This analysis involves the load factor a, which is the ratio of the current number of items in the table to the maximum size of the array : That is, a = current number o f table items / TableSize a is a measure of how full the hash table T is. As T fills, a increases and the chance of collision increases, so search times increase. Thus, hashing efficiency decreases as a increases. Unlike the efficiency of earlier table implementations, the efficiency of hashing does not depend solely on the number N of items in the table. While it is true that for a fixed TableSize, efficiency decreases as N increases , for a given N you can make T larger to increase efficiency. Thus, when choosing TableSize, you should estimate the largest possible N and select TableSize so that a is small. It is recommended that a should not exceed 2/3. Hashing efficiency for a particular search also depends on whether the search is successful. An unsuccessful search requires more time in general than a successful search. This method involves the simplest use of additional memory to reduce retrieval time is to add a link field to each table entry. This field contains the next position of the table to examine in searching for a particular item. In this method a rehash function is not required at all, it is therefore an example of the second major method for collision resolution, called chaining. This method uses links rather than a rehash function to resolve hash clashes. The simplest of the chaining method is called standard coalesced hashing. A search and insertion algorithm for this method can be represented as follows. Assume that each table entry contains a key field k initialized to a NULLKEY and the next field initialized to –1.The algorithm uses an auxiliary function getempty, which returns the index of an empty table locations. PSEUDOCODIC VERSION OF THE COALESCED HASHING
while(k(i) != key && next(i)>=0) i=next(i); if(k(i)= = key) return(i);
if(k(i)= = NULLKEY) //The hash position is empty j=i;
j=getempty(); next(i)=j;
k(j)= = key; k(j)= = rec; return(j);
The function getempty can use any technique to locate an empty position.The simplest method is to use a variable avail initialized to tabelsize-1 to execute.
while(k(avail)!=NULLKEY) avail--; return(avail); External searching is restricted primarily to those techniques, which are based on hashing. The hashing techniques can be applied successfully to internal table. One of the serious drawbacks of hashing for the external storage is that it is in sufficiently flexible. Unlike the internal databases are semi-permanent structures that are not usually created and destroyed within the lifetime of a single program. Further, the contents of an external storage structure tend to grow and shrink unpredictably. A scheme should be introduce that too much extra space when a file is small but permits efficient access as it grows larger. Two such scheme are called Dynamic Hashing, attributable to Larson, and Extendible to Fagin, Nievergelt, Pippenger, and Strong. In extendible hashing, each bucket contains an indication of the number of bits of h(key) that determine which records are in the bucket. This number is called the bucket depth. Initially, this number is b for all the bucket entries, it is increased by 1 each time a bucket splits. To locate the number in the Extendible hashing, compute h(key) and use the first d bits (where d is the index depth) to obtain a position in the index. The contents of this position point to the bucket containing the desired record if it exists. It is more time efficient, since a tree path need not to be transversed as in the dynamic hahsing. ILLUSTRATION AND EXAMPLE A bucket is a structure containing an array of records, a count of the number of records actually occupied, and a bucket depth, which indicates the number of significant bits used to address into this bucket. The address into the directory. That is, 2directory_depth is the size of the directory. The hash function is used as follows: directory_depth many bits are selected from hash(key), and these are used to index into the directory. Often these are the low order bits of hash(key), but with a good hash function, one could use the high order bits.
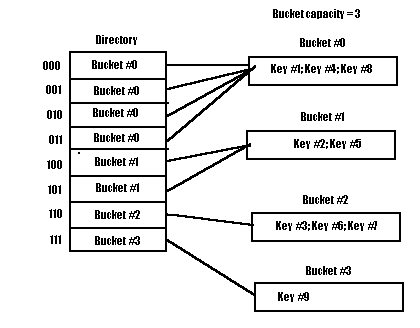
If we insert Key #10, which hashes to 010..., we wind up in Bucket #0, which is full. Since the bucket depth is less than the directory depth, we do not need to add directory entries, but we do split the bucket. We create a new Bucket #4. Now Buckets #0 and #4 will have bucket depth 2. All keys that hash to 00... must be placed in Bucket #0, and all keys that hash to 01... must be placed in Bucket #4. The directory entries must be revised accordingly. Thus, assume that Key #1 hashes to 001..., Key #4 hashes to 011..., Key #8 to 000..., and Key #10 to 011.... We move the keys that hash to 01... to Bucket #4. The changes are indicated in red below. Now consider the following example, in which the directory depth is 2. If Key #6 hashes to 11.., then we must split Bucket #4 since the bucket depth equals the directory depth, we will have to double the directory. There will be a new Bucket #3. Keys that hash to 110... will be placed in Bucket #2, and keys that hash to 111... will be placed in Bucket #3. The other directory entries must be duplicated. For example, keys that hash to either 100... or 101... will still be in Bucket #1. The picture that follows shows the result.
DYNAMIC HASHING One of the principle drawbacks of conventional hashing as a mean of organizing external files for fast access is that the size of the hash table must be eliminated in advance. Two problems can arise:
Knott (1971), Hopgood (1968) suggested that all keys should be rehashed to a new table of appropriate size and provided an algorithms for deciding when this rehashing should take place. The table is completely rehashed if this decrease in search time is greater than the cost of rehashing the complete table is the best way of improving the performance of a hash table. Dynamic Hashing Techniques, which avoid the costly rehashing of the whole file by changing the hashing, function rather than moving a large number of records. Virtual Hashing Litwin (1978) proposed a new type of hashing called Virtual Hashing and Litwin (1978) presented a performance measurements for the method. Litwin suggests that the term Virtual Hashing refers to any hashing function with dynamically adapt to changes in the table being accessed. When Virtual Hashing is used the size of the table is doubled whenever the table becomes too full. A new hashing function is used with those buckets in the original table that flows. These new hashing function maps some of the records of an overflowing bucket to the corresponding bucket in the new half of the table. A bit tables are used to indicate with which positions the new hashing function is employed. Spiral Hashing Martin (1979) proposed spiral hashing another hashing techniques suitable for the hash tables, which vary in size. The name Spiral Hashing is derived from considering memory space to be organized in a spiral rather than in a line. The table can be contracted in an analogous manner by rehashing keys at the outer end to inner positions. The proportion is called the growth factor, g. A spiral hash table occupies one revolution outward from its starting point. To obtain a starting point, an arbitrary number of revolutions, s is chosen and the starting location is specified as [gs]. To expand the hash table, s is increased in value and to connect it s is decreased. Martin (1979) suggested that the location separated by spiral hashing be treated as locations within a large virtual space. Location in the virtual space can be mapped to a smaller constant origin address space. Therefore a boundary of a constant origin address space is fixed and the other boundary with the current size of the hash table. Theorem 1 In a hash table where collisions are resolved by chaining, an unsuccessful search takes Big-Sigma (1+Load Factor) time, under the assumption of uniform hashing. Proof A key is equally likely to hash into any of the M slots. The average time to search unsuccessfully for a key is the average time it takes to search to the end of a linked list. The average length of the list is exactly the Load Factor (L=n/m). Therefore, the expected number of elements examined in an unsuccessful search is L and the total time is L+1, including the time to compute h(k). Theorem 2 In a hash table in which collisions are resolved by chaining, a successful search takes O(1+Load Factor) time. Assuming, of course, we have Simple Uniform Hashing. To make this proof easier to understand, I am assuming that the CHAINED-HASH-INSERT() function inserts a new element at the end of the list instead of at the front. Proof You have to assume that the key being searched for is equally likely to be any of the N keys stored in the table. The expected number of elements inspected during a successful search is 1 more than the length of the list when the sought-for element was inserted. To find the expected number of elements examined, you take the average over N items in the of 1+the expected length of the linked list to which the I'th element was added. The expected length of the list is (i-1)/m. And, of course, here is the solution: 1+(n/2m)-(1/2m) = 1+(Load Factor/2)-(1/2m) = O(1+Load Factor) Therefore, the total amount of time required for a successful search is: 1+(Load Factor/2)-(1/2m) = 2+(Load Factor/2) - (1/2m) = O(1+Load Factor) DEFINITIONArray An array is a collection name given to a group of similar quantities. Average Length Search (ALOS) A performance measure is needed to compare different hashing function and the measure most widely adopted is the Average Length of Search (ALOS). Bucket A structure associated with a hash address that can accommodate more than one item. An array of buckets can be used as a hash table to resolve collision. Chaining The technique, called chaining, builds a linked list of all items whose keys hash to the same values. Collision Resolution Techniques When this situation arises the colliding records must be sorted and accessed as determined by Collision Resolution Techniques. There are two broad classes of such techniques open addressing and chaining. Digit Analysis A hashing function is referred to as Digit Analysis if it forms addresses by selecting and shifting digits or bits of the original keys. Double Hashing A collision-resolution scheme that can use two hash functions. The hash function is search for an unoccupied location, starting from the location that one hash function determines and considering every nth location, where n is determined from a second hash function. Efficiency Dynamic hashing To locate a record under dynamic hashing, compute h(key) and use the first b bits to locate a root node in the original index. Extendible hashing Each bucket contains an indication of the number of bits of h(key) that determine which records are in the bucket. Folding Method In the Folding method a key is partitioned into a number of parts each of which has the same length as the required with the possible exception of the last part. Hash Collision Two records cannot occupy the same position. Such a situation is called a hash collision or a hash clash. Hash Function A function that maps the search key of a table item into a location that will contain the item. Hashing A method that enables access to table items in time that is relatively constant and independent of the items by using the hash function and a scheme for resolving collisions. Hash Key If a record whose key hashes into hr, hr is called the hash key of r. Linear Probing A collision-resolution scheme that searches the hash table sequentially, starting from the original location specified by the hash function, for an occupied location. Mid Square method In this method a key is multiplied by itself and the address is obtained by selecting an appropriate number of bits or digits from the middle of the square. Quadratic Probing A collision-resolution scheme that searches the hash table for an occupied location beginning with the original location that the hash function specifies and continuing at increments of 1,2,3,4, …. Rehashing The technique called rehashing, involves using a secondary hash function on the hash key of the item. Separate Chaining A collision-resolution scheme that uses an array of linked lists as a hash table. The ith linked list or chain contains all items that maps into location i. Spiral Hashing The name Spiral Hashing is derived from considering memory space to be organized in a spiral rather than in a line. The table can be contracted in an analogous manner by rehashing keys at the outer end to inner positions. Virtual Hashing Virtual Hashing refers to any hashing function with dynamically adapt to changes in the table being accessed. BIBLOGRAPHYAn Introduction to Data Structure with Applications Second Edition Jean-Paul Tremblay Paul G.Sores Chapter # 3: Linear Data Structure & the Sequential Storage representation Chapter # 7: File Structure – Linear Searching An Introduction to Data Structure with applications ( Computer Science Series) Second Edition Tremblay Sorsen Chapter # 6: Sorting & Searching Chapter # 7-11: File Structure Data Structure An Object Oriented Approach Lafayette College William J. Collins Chapter # 10: Hashing Data Structure and Program Design Third Edition Robert L. Kruse Chapter # 9: Tables and Information Retrieval Data Structures Using C & C++ Second Edition Yediday Langsam Moshe J. Augenstein Aaron M. Tenenbaum Chapter 7: Hashing Data Structures and Algorithm Analysis in C++ Mark Allen Weiss Chapter 5: Hashing Data Abstraction And Problem Solving with C++ Walls & Mirrors Frank M. Carrano Chapter 12: Advanced Implementation of Tables
|
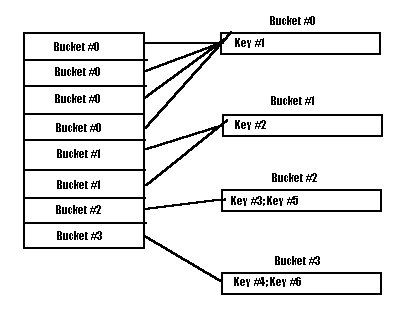
 In the example shown
below, the directory depth is 3. The depth of Bucket #0 is 1, the depth of Bucket #1 is 2,
and the depth of Buckets #2 and #3 is 3. The search for a key proceeds as follows. If we
find that Key #2 hashes to the bit string 101..., we index to directory entry 101, and
follow the pointer to Bucket #1. The number of bits we use of the hash value is the
directory depth.
In the example shown
below, the directory depth is 3. The depth of Bucket #0 is 1, the depth of Bucket #1 is 2,
and the depth of Buckets #2 and #3 is 3. The search for a key proceeds as follows. If we
find that Key #2 hashes to the bit string 101..., we index to directory entry 101, and
follow the pointer to Bucket #1. The number of bits we use of the hash value is the
directory depth.